从底层角度理解引用
本篇主要从底层角度理解一下引用工作机制。
C++的引用及与指针的区别
引用是C++中出现的概念,而指针是C语言中的概念,前者兼容后者(简单的说就是在.c文件中使用引用会报错)
引用
引用的使用示例,核心语法type& ref = type var;
1 | |
引用的特点:
- 引用时必须进行初始化,即创建时就必须绑定到一个变量上。
- 引用一旦绑定到某个对象,就无法再修改其指向。
- 引用是绑定变量的一个别名,通过引用可以直接修改原变量的值。
引用与指针
可以借助指针理解一下引用(关于指针更多的内容见[对C语言指针的底层理解])。
二者的本质区别
指针:指针是一个独立变量,它占据一份内存地址,它存储另一个变量的地址,通过修改它的值,可以让它指向不同的对象。
引用:引用是一个别名,它是某个变量的另一个名字,它在语法上通常不占据内存空间。
以下面的代码为例:
1 | |
如果我们使用visual studio对上面代码进行调试,当程序执行到return 0;时,借助调试器观察变量的值,会发现x和r的结果是一样的,说明当执行r = 20时,实际上是修改的x。

同时,打印结果如下所示:
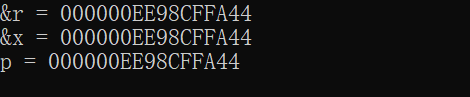
但是结合编译器反汇编得到的汇编代码,可以发现一个有意思的事情:
1 | |
x = 30的反汇编代码是C7 45 04 1E 00 00 00,其中C7指代mov操作,后4个字节是立即数30,中间的45 04则是x的寻址,是通过指定x在栈中的偏移量的形式获取x的地址的。*p = 10是通过指针的形式修改x的值,它的反汇编程序则分为两句话,首先mov rax, qword ptr [p],获取p存储的内存地址加载到rax中,再将立即数10存储到rax的地址中。第一句汇编对应的二进制编码是48 8B 45 28,其中45 28指代p在栈中的位置,从这里可以看出p和x占据两块内存。有意思的是,按照对引用的理解,
&r == &x,似乎执行r = 20和执行x = 30应该没有什么区别,但是r = 20的汇编语句实际上与指针赋值的汇编语句是相似的,它的第一句话mov rax, qword ptr [r],二进制编码是48 8B 45 48,说明在内存中r是占据了一块地址的,这块地址在栈中的偏移量是45 48。
我们还可以通过调试工具的内存信息验证第三条的理解:下图所示,x的地址是0x000000EE98CFFA44,而在这片内存中有两个区域存放了x的地址,第一个区域和x地址的偏移量恰好是0x24,也就是*p的偏移地址和x的偏移地址之间的距离;而第二区域和x地址的偏移量恰好是0x44,也刚好是前面二进制编码信息中r和x的地址的距离。
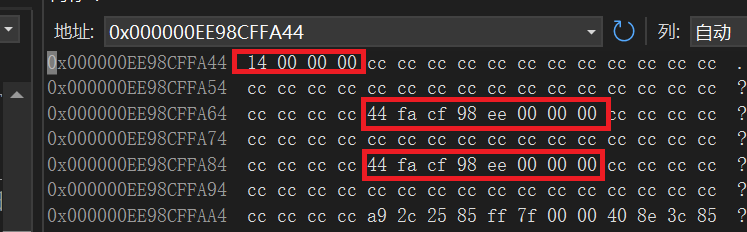
以上信息说明,尽管在语法上认为引用是原始变量的一个别名,通过直接取地址的方式也只能获取到相同的地址,但是在编译器内部,依旧是通过指针的方式来处理引用的,也就是说本质上引用还是占据了一份内存的,只是这部分内存不会对编程人员开放——这也恰恰说明了引用的优点:因为无法直接访问内存,使用起来会更加安全。
语法和使用差异
- 初始化:
- 指针创建时可以不进行初始化,支持动态分配。
- 引用在创建时必须绑定到一个对象,不能绑定到
NULL或者未进行初始化的变量。
1 | |
- 重新绑定:
- 指针可以随时修改它的值,随时可以指向另一个变量。
- 引用一旦绑定一个变量,就无法再更改绑定对象。
1 | |
- 功能差异
- 指针具有更高的动态性,可以用于动态内存分配,数组操作。
- 引用更适合简化函数参数传递、返回值等场景。
总结
以一个常规的交换例子看一下二者在函数调用时传参的区别:
1 | |
对引用的深入理解
左值与右值
左值
左值:可以获取地址的值,也就是在程序运行期间有确定存储位置的对象。
特点:
- 可以出现在赋值符号(=)的左侧,也可以出现在赋值符号的右侧。
- 占据一块存储空间,可以通过取地址符号(&)获取该变量的地址。
示例:如下
x、p和数组arr都是左值。
1 | |
右值
- 右值:是一个数据的表达式,在程序运行期间没有确定存储位置的临时值,例如字符常量,函数返回值等。
- 特点:
- 右值通常是临时的,在程序运行之后会被销毁。
- 右值不能出现在等号的左侧,也就是不能被赋值
- 不能对右值直接进行取地址(例如不可以写&42)
- 示例:
1 | |
总结
- 左值一般是开发者自定义的变量,在变量创建时就会开辟一块内存,后续可以修改这片内存的值(const定义除外),这块内存在其生命周期结束的时候销毁,例如函数内的变量会在函数运行结束之后销毁。
- 右值一般为临时变量,是程序运行间的产物,内存是由编译器开辟的,生命周期通常只在当前语句。
- 对于一些常量,会存储在内存的只读区域。
左值引用与右值引用
顾名思义,左值引用是对左值的引用,右值引用是对右值的引用。
左值引用是C++一开始就有的特性,右值引用是C++11才出现的特性。
左值引用
左值引用就是对左值的引用,也就是对左值起别名。
以下代码中,a 、p 、*p都是左值,ra、rpa 、rp 分别是这三个左值的左值引用。
1 | |
右值引用
右值引用就是对右值的引用,即给右值取别名,右值引用的语法为对右值加上两个&。
以下代码中,10、m+n 和 int_max(m,n)的返回值都是右值,r1、r2 和 r3 分别是这个三个右值的引用。
1 | |
总结与分析
如何理解引用的地址
首先,不管是左值引用还是右值引用,从语法上来讲,都是对一段空间取别名。左值引用比较好理解,对左值取引用,能找到一块空间(是定义该左值时开辟的空间),那么对右值引用来说,既然右值不能取地址,那么右值引用是如何绑定一块内存空间的呢?
前面说过,右值也是有地址的(不能取地址不代表不占据内存),当我们创建一个右值时,理论上程序执行到创建右值的下一句时,这个右值占据的空间就会被释放,而右值引用就是告诉编译器程序员要求继续使用这块空间,从内存的角度上,编译器会开辟一段空间给右值引用,并把这个右值的地址保存到这块空间中。
因此,右值引用实际上是一个可以取地址的左值。
用代码检验一下,能看到既能对右值引用b 取地址,也能通过操作b 修改这块内存上的值。
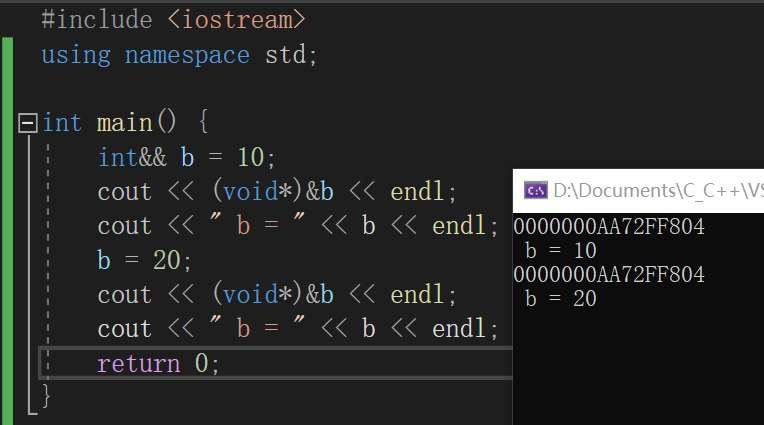
还可以去看一下这块内存:
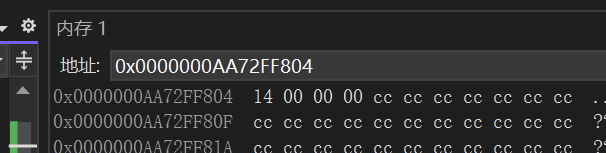
接下来将左值引用和右值引用放在一起做一下对比:
左值引用和右值引用本质上是相似的,前者是将引用与用户创建的空间绑定在一起,后者是通过引用的方式,保留了原本要被销毁的信息。
有如下代码:
1 | |
前三行创建左值、左值引用、右值引用对应的汇编如下,可以看出其实 int&& r = 10;和 int m = 10; int& rm = m;本质是一样的,都是开辟一段空间,再把这段空间的地址保存到另一块空间中。
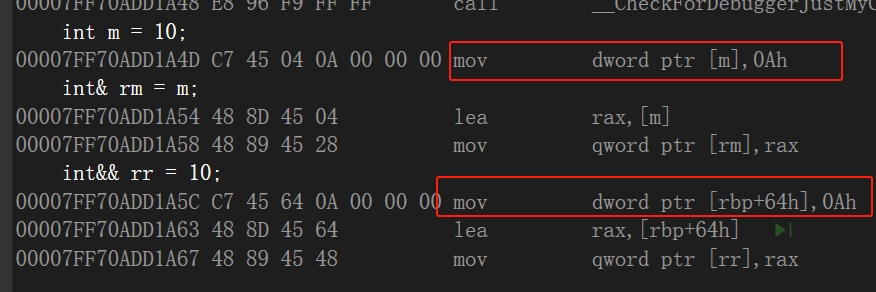
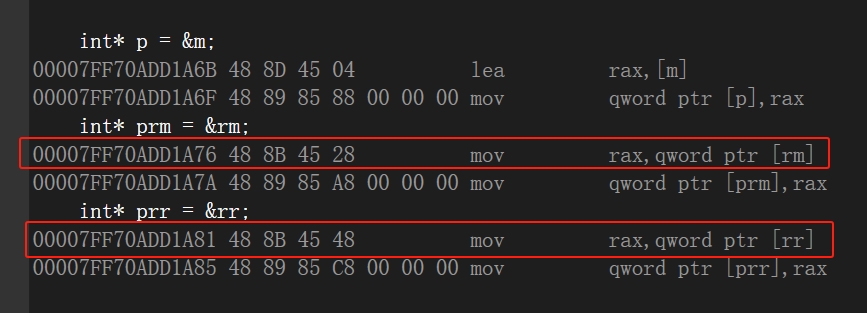
再根据创建指针这部分的汇编代码观察一下细节,能看出来m和rm本质上在内存中不是同一块地址,同样的rr和没有销毁的右值空间也不是一块地址,但是最后从语法的角度,却能实现&m == &rm,这一任务是由编译器去完成的,程序员只需要牢记引用是绑定变量的一个别名即可,而内部的实现还是以指针的形式进行的:即引用在内存中体现为一个指针,c++中对引用取地址时,编译器实际上是获取的这个指针上存储的地址信息。
总之,左值引用和右值引用都是有额外的一段内存空间的,但是不对程序员开放,也无法对这块内存空间进行修改,这也就解释了为什么引用一旦绑定就无法修改绑定对象。
引用的互相转换
左值引用 引用 右值
添加const关键字即可实现左值引用 引用右值
1 | |
右值引用 引用 左值
通过强制转换的形式实现右值引用 引用 左值
1 | |
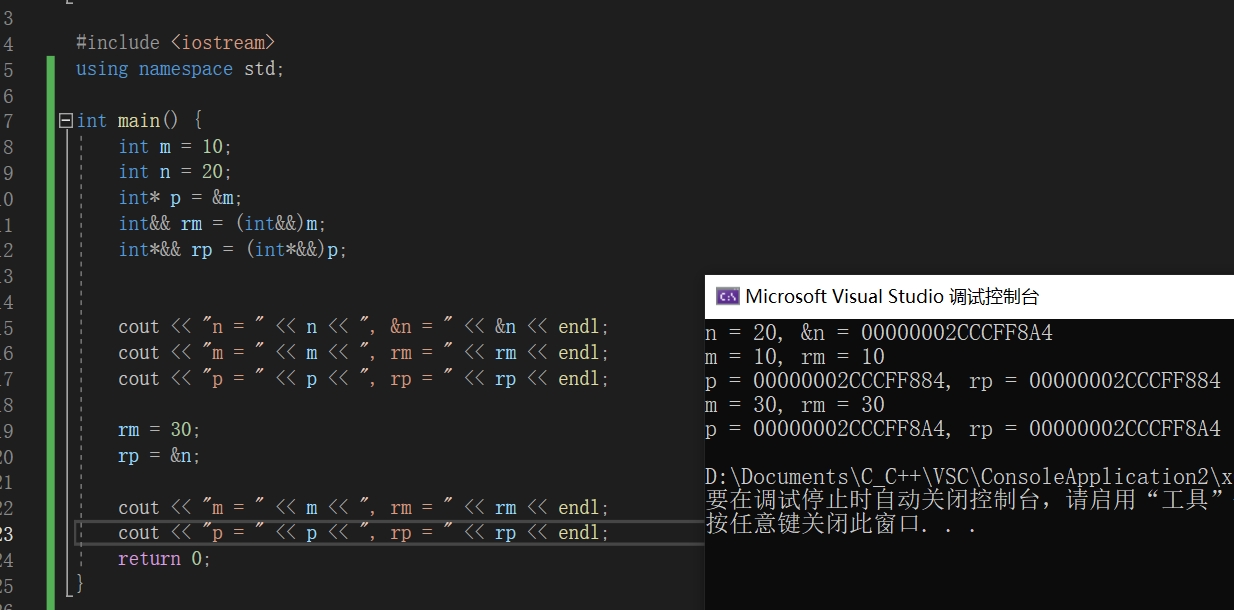
转换之后,rm指代 m,rp指代p。用以下代码进行一些验证:
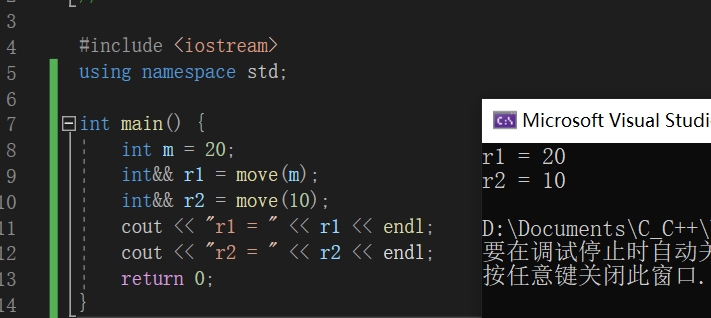
std::move转换方式
std::move(a)里面的a无论是左值还是右值,都会被转换成右值。
总结
- 左值引用与右值引用的相同点:
- 都是对一段空间取别名,一旦绑定一段空间,不可以改变绑定对象。
- 底层都是指针实现,区别在于语法层面。
- 除了使用
const关键字,都可以通过直接操作引用来达到改变原始对象的目的。
- 左值引用与右值引用的不同点:
- 左值引用引用左值,左值可以修改;右值引用引用右值,右值不可以修改
- 左值是由用户自定义变量组成,右值一般为编译器运行时开辟临时变量。
最后,因为一直都不理解为什么无法获取引用的地址——怎么会有个变量没有占据内存呢,既然占据了内存就应该能找到地址啊——于是就边学习边整理了本篇的内容。
但是,引用应该有更多可以深挖的地方,比如在哪些场景可以使用引用而不是指针,此时内存的工作状态是什么样子的;比如各类传参的性能对比;比如右值引用在c++11出现,它的特殊性是什么;比如引用转换函数move的底层实现等等,但这些都需要更复杂的cpp知识,只能边学习边填坑了。
cpp的魅力无限!(doge)